
آنتروپیک اخیراً آخرین مدل غزل کلود 3.5 خود را منتشر کرد و ادعا کرد که ChatGPT 4o و Gemini 1.5 Pro را در چندین بنچمارک شکست می دهد. بنابراین برای آزمایش این ادعا، به این مقایسه دقیق رسیده ایم. درست مانند مقایسه قبلی ما بین Claude 3 Opus، GPT-4 و Gemini 1.5 Pro، ما قابلیت استدلال، استدلال چندوجهی، تولید کد و موارد دیگر را ارزیابی کردهایم. در این یادداشت، بیایید شروع کنیم.
1. زمان خشک شدن را پیدا کنید
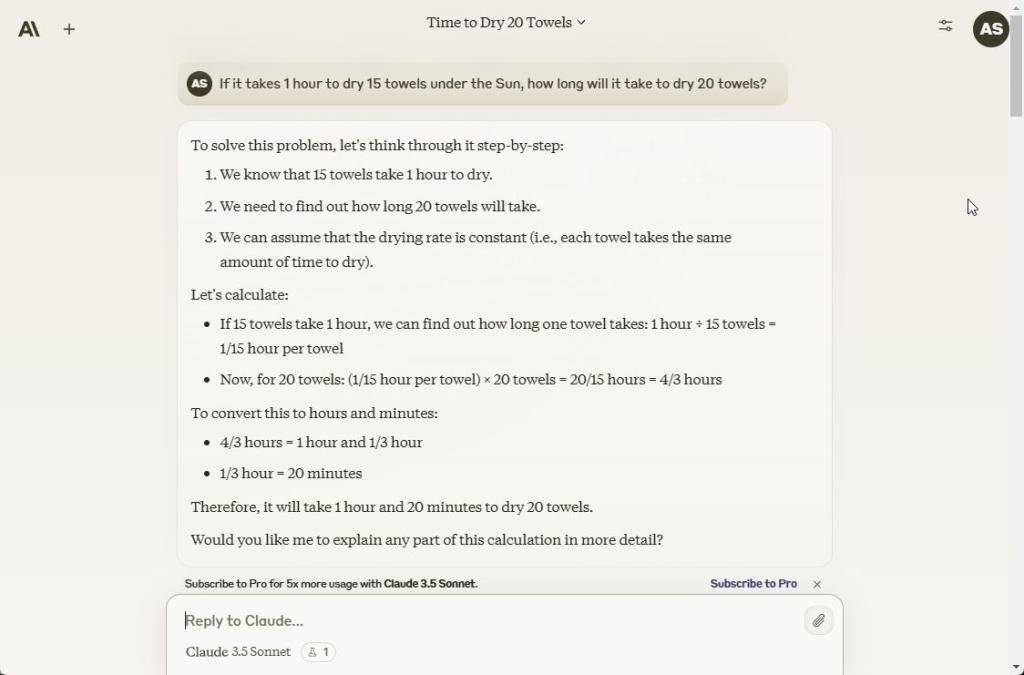
اگرچه این یک سوال اساسی به نظر می رسد، من همیشه تست خود را با این سوال استدلالی پیچیده شروع می کنم. LLM ها معمولاً آن را اشتباه می گیرند. کلود 3.5 غزل نیز همین اشتباه را مرتکب شد و با استفاده از ریاضی به سؤال پرداخت. مدل می گوید خشک کردن 20 حوله 1 ساعت و 20 دقیقه طول می کشد که نادرست است. ChatGPT 4o و Gemini 1.5 Pro به درستی پاسخ دادند و گفتند که خشک کردن 20 حوله همچنان 1 ساعت طول می کشد.
If it takes 1 hour to dry 15 towels under the Sun, how long will it take to dry 20 towels?
برنده: ChatGPT 4o و Gemini 1.5 Pro
مقالات مرتبط
ChatGPT 4o در مقابل ChatGPT 4: ویژگی های ممتاز به صورت رایگان؟
آرجون شا
17 مه 2024
2. وزن را ارزیابی کنید
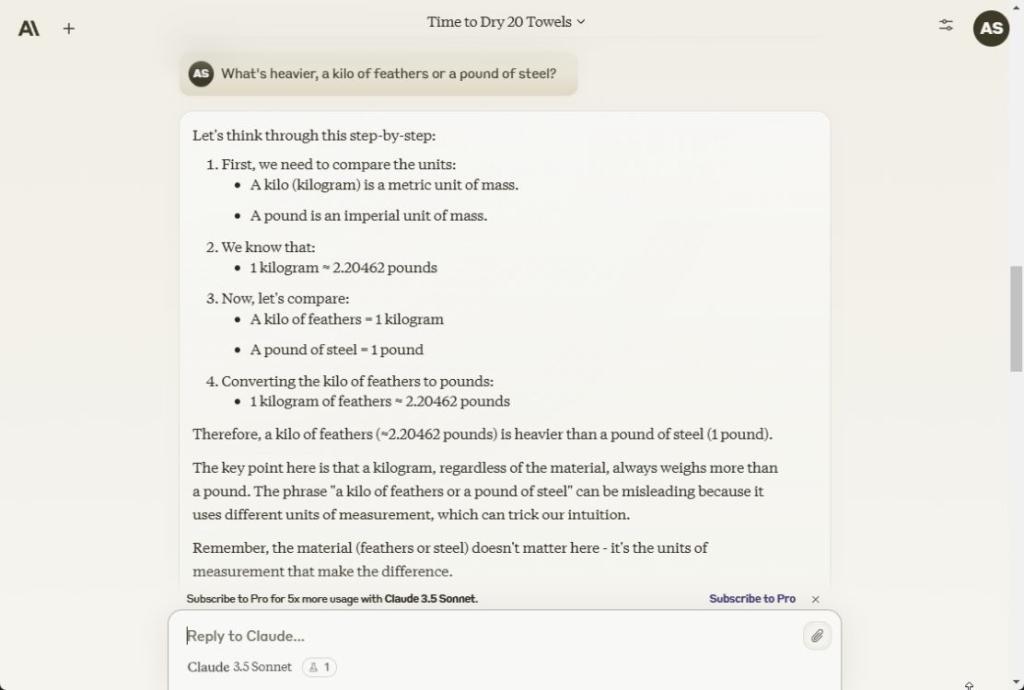
در مرحله بعد، در این سوال استدلال کلاسیک، خوشحالم که گزارش دهم که هر سه مدل از جمله Claude 3.5 Sonnet، ChatGPT 4o و Gemini 1.5 Pro به درستی پاسخ دادند. یک کیلو پر یا هر چیز دیگری همیشه سنگین تر از یک پوند فولاد یا مواد دیگر خواهد بود.
What's heavier, a kilo of feathers or a pound of steel?
برنده: غزل Claude 3.5، ChatGPT 4o و Gemini 1.5 Pro
3. پازل کلمات
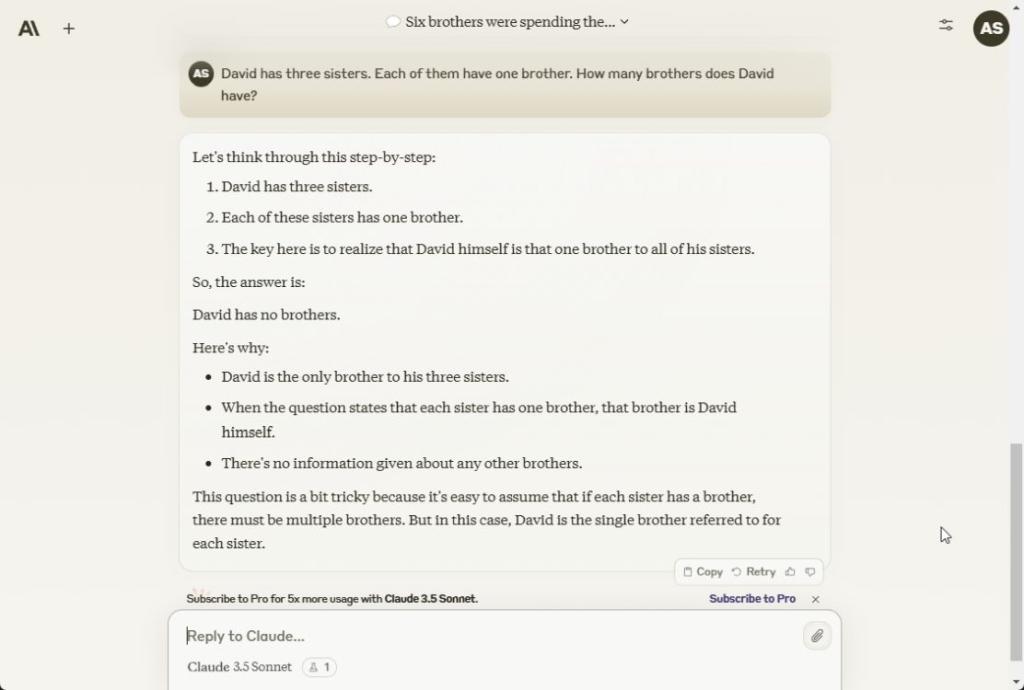
در آزمون استدلال بعدی، کلود 3.5 Sonnet به درستی پاسخ می دهد که دیوید هیچ برادری ندارد و او تنها برادر در بین خواهر و برادر است. ChatGPT 4o و Gemini 1.5 Pro نیز پاسخ درست را دریافت کردند.
David has three sisters. Each of them have one brother. How many brothers does David have?
برنده: غزل Claude 3.5، ChatGPT 4o و Gemini 1.5 Pro
مقالات مرتبط
6 چیز جالبی که ChatGPT 4o می تواند انجام دهد که OpenAI آن را برجسته نکرده است
آرجون شا
14 مه 2024
4. موارد را مرتب کنید
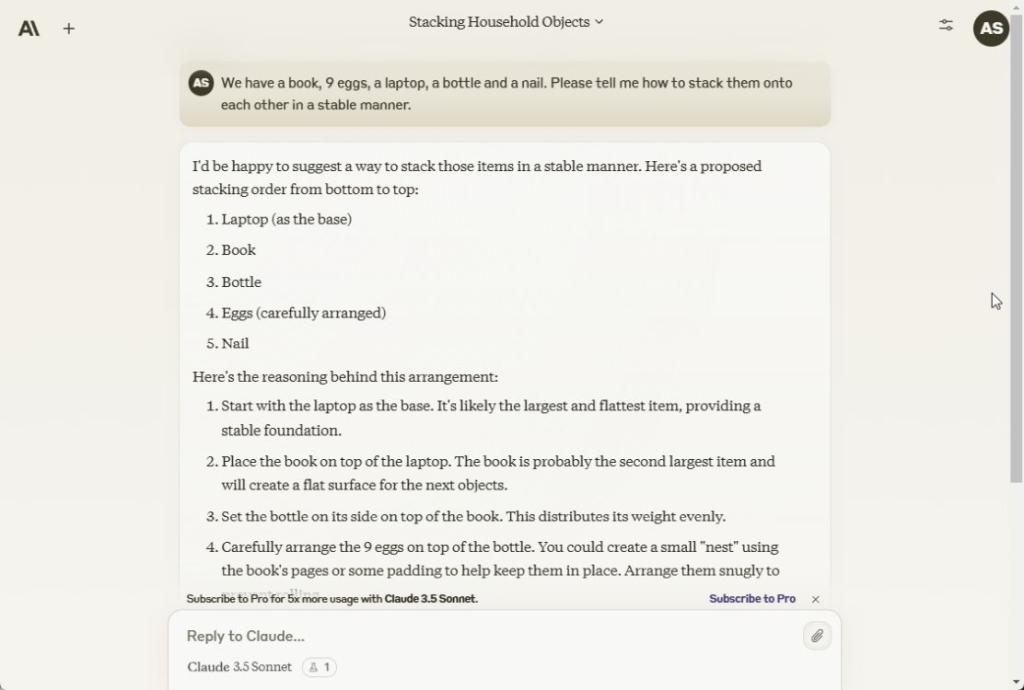
پس از آن، از هر سه مدل خواستم که این موارد را به صورت ثابت بچینند. افسوس که هر سه اشتباه کردند. مدلها رویکردی مشابه داشتند: ابتدا لپتاپ، سپس کتاب، بطری بعدی و سپس 9 تخممرغ را روی پایه بطری قرار دهید، که غیرممکن است. برای اطلاع شما، مدل قدیمی GPT-4 به درستی پاسخ داده است.
Here we have a book, 9 eggs, a laptop, a bottle and a nail. Please tell me how to stack them onto each other in a stable manner.
برنده: هیچ یک
5. دستورالعمل های کاربر را دنبال کنید
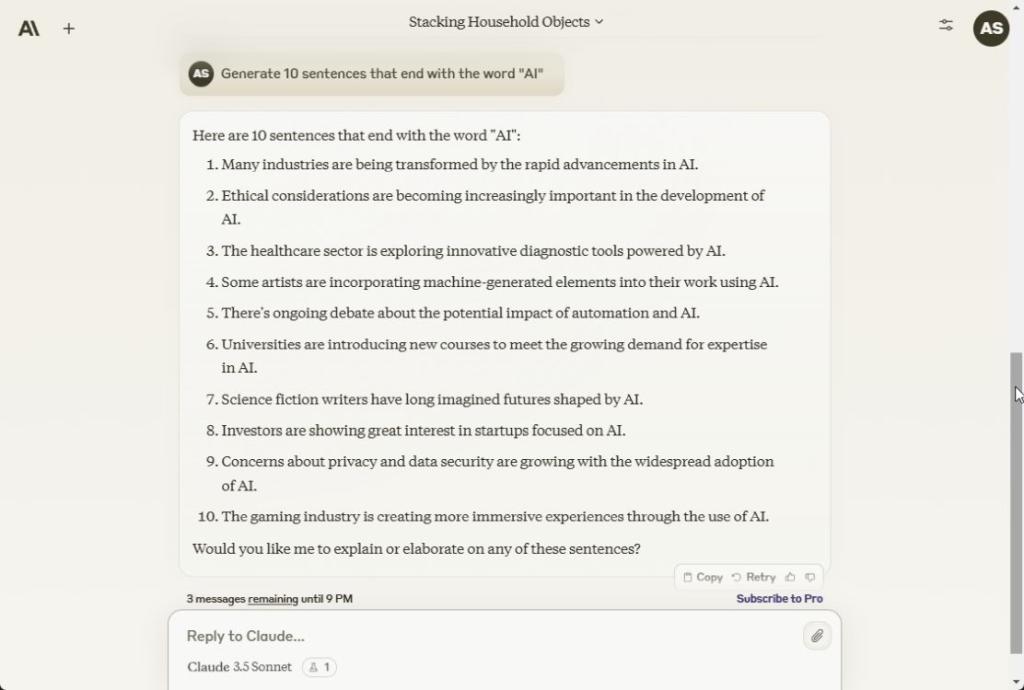
Anthropic در پست وبلاگ خود اشاره کرد که کلود 3.5 Sonnet در پیروی از دستورالعمل ها عالی است و به نظر می رسد درست باشد. تمام 10 جمله ای که با کلمه “AI” ختم می شوند را ایجاد کرد. ChatGPT 4o نیز آن را به درستی 10/10 دریافت کرد. با این حال، Gemini 1.5 Pro تنها می تواند 5 جمله از 10 جمله را تولید کند. گوگل باید این مدل را برای آموزش بهتر هدایت کند.
Generate 10 sentences that end with the word "AI"
برنده: کلود 3.5 غزل و ChatGPT 4o
مقالات مرتبط
Gemini 1.5 Flash یک جواهر کم ارزش است که باید همین الان امتحان کنید: در اینجا چگونگی
آرجون شا
20 مه 2024
6. سوزن را پیدا کنید
آنتروپیک یکی از اولین شرکت هایی بوده است که طول زمینه بزرگی را ارائه کرده است، از 100 هزار توکن تا اکنون 200 هزار پنجره زمینه. بنابراین برای این تست، یک متن بزرگ با 25 هزار کاراکتر و حدود 6 هزار توکن تغذیه کردم. یه سوزن یه جایی وسط اضافه کردم.
من در مورد سوزن هر سه مدل سوال کردم، اما فقط کلود 3.5 سونت توانست بیانیه خارج از محل را پیدا کند. ChatGPT 4o و Gemini 1.5 Pro نتوانستند سوزن را پیدا کنند. بنابراین برای پردازش اسناد بزرگ، من فکر می کنم Claude 3.5 Sonnet مدل بهتری است.
برنده: غزل کلود 3.5
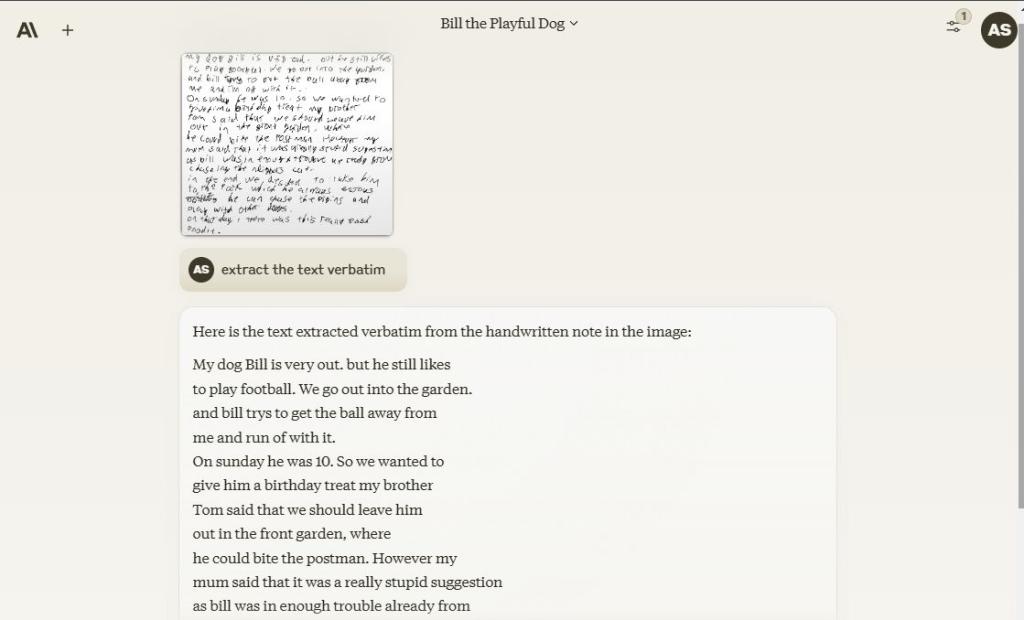
7. تست بینایی
برای آزمایش قابلیت بینایی، تصویری از دست خط ناخوانا را آپلود کردم تا ببینم مدلها چقدر میتوانند شخصیتها را شناسایی کرده و آنها را استخراج کنند. در کمال تعجب، هر سه مدل کار بسیار خوبی انجام دادند و متون را به درستی شناسایی کردند. تا آنجا که به OCR مربوط می شود، هر سه مدل کاملاً توانمند هستند.
برنده: غزل Claude 3.5، ChatGPT 4o و Gemini 1.5 Pro
مقالات مرتبط
من با استفاده از ChatGPT 4o در چند ثانیه یک بازی ساختم و شما هم می توانید
آرجون شا
16 مه 2024
8. یک بازی بسازید
بالاخره به دور آخر می رسیم. در این تست، من تصویری از بازی کلاسیک تتریس را بدون فاش کردن نام آپلود کردم و به سادگی از مدل ها خواستم که یک بازی شبیه به این را در پایتون ایجاد کنند. خوب، هر سه مدل به درستی بازی را حدس زدند، اما فقط کد تولید شده Sonnet با موفقیت اجرا شد. هر دو ChatGPT 4o و Gemini 1.5 Pro نتوانستند کد بدون اشکال تولید کنند.

در یک شات، بازی با استفاده از کد Sonnet با موفقیت اجرا شد. فقط باید نصبش کنم pygame کتابخانه بسیاری از برنامه نویسان از ChatGPT 4o برای کمک به کدنویسی استفاده می کنند، اما به نظر می رسد که مدل Anthropic ممکن است مورد علاقه جدید در بین کدنویسان باشد.
Claude 3.5 Sonnet در معیار HumanEval که توانایی کدنویسی را ارزیابی می کند، امتیاز 92% را کسب کرده است. در این معیار، GPT-4o 90.2 درصد و Gemini 1.5 Pro با 84.1 درصد است. واضح است که برای کدنویسی، یک مدل SOTA جدید در شهر وجود دارد و آن مدل کلود 3.5 Sonnet است.
برنده: غزل کلود 3.5
نتیجه
پس از اجرای تست های مختلف بر روی هر سه مدل، احساس می کنم که کلود 3.5 Sonnet به خوبی مدل ChatGPT 4o است، اگر نگوییم بهتر است. به ویژه در کدنویسی، مدل جدید آنتروپیک به طور جدی چشمگیر است. نکته قابل توجه این است که آخرین مدل Sonnet حتی بزرگترین مدل آنتروپیک نیست.
مقالات مرتبط
غزل Anthropic Claude 3.5 منتشر شد. ChatGPT 4o را شکست می دهد
آرجون شا
21 ژوئن 2024
ابرهوش ایمن چیست و چه کاری انجام می دهد
آرجون شا
20 ژوئن 2024
این شرکت میگوید Claude 3.5 Opus اواخر امسال عرضه میشود که باید عملکرد بهتری هم داشته باشد. Gemini 1.5 Pro گوگل نیز بهتر از آزمایشهای قبلی ما عمل کرد که به این معنی است که به طور قابل توجهی بهبود یافته است. به طور کلی، میتوانم بگویم که OpenAI تنها آزمایشگاه هوش مصنوعی نیست که کار بزرگی در زمینه LLM انجام میدهد. غزل کلود 3.5 آنتروپیک گواهی بر این واقعیت است.
با کُلبه وبسایت و مجله فناوری و ابزارهای هوشمند ،بهترین تکنولوژی، بهترین آینده ، بروز بمانید