
متا اخیراً مدل Llama 3 خود را در دو اندازه با پارامترهای 8B و 70B معرفی کرده و مدلها را برای جامعه هوش مصنوعی منبع باز کرده است. در حالی که Llama 3 یک مدل کوچکتر 70B است، همانطور که از تابلوی امتیاز LMSYS مشهود است، توانایی چشمگیری را نشان داده است. بنابراین ما Llama 3 را با مدل پرچمدار GPT-4 مقایسه کرده ایم تا عملکرد آنها را در تست های مختلف ارزیابی کنیم. در این یادداشت، اجازه دهید مقایسه خود بین Llama 3 و GPT-4 را مرور کنیم.
1. تست آسانسور جادویی
بیایید ابتدا آن را اجرا کنیم تست آسانسور جادویی برای ارزیابی قابلیت استدلال منطقی Llama 3 در مقایسه با GPT-4. و حدس بزنید چه؟ Llama 3 به طور شگفت انگیزی امتحان را پشت سر گذاشت در حالی که مدل GPT-4 پاسخ صحیح را ارائه نمی دهد. این بسیار تعجب آور است زیرا Llama 3 تنها بر روی 70 میلیارد پارامتر آموزش دیده است در حالی که GPT-4 بر روی 1.7 تریلیون پارامتر عظیم آموزش داده شده است.
به خاطر داشته باشید، ما آزمایش را روی مدل GPT-4 میزبانی شده در ChatGPT (در دسترس کاربران پولی ChatGPT Plus) انجام دادیم. به نظر می رسد که از مدل قدیمی تر GPT-4 توربو استفاده می کند. ما همین آزمایش را روی مدل GPT-4 که اخیراً منتشر شده است (gpt-4-turbo-2024-04-09) از طریق OpenAI Playground، و آزمون را با موفقیت پشت سر گذاشت. OpenAI می گوید که آنها آخرین مدل را برای ChatGPT عرضه می کنند، اما شاید هنوز در حساب ما موجود نباشد.
There is a tall building with a magic elevator in it. When stopping on an even floor, this elevator connects to floor 1 instead.
Starting on floor 1, I take the magic elevator 3 floors up. Exiting the elevator, I then use the stairs to go 3 floors up again.
Which floor do I end up on?
برنده: Llama 3 70B و gpt-4-turbo-2024-04-09
توجه داشته باشید: GPT-4 در ChatGPT Plus شکست می خورد

2. محاسبه زمان خشک کردن
بعد، کلاسیک را اجرا کردیم سوال استدلالی برای تست هوش هر دو مدل در این آزمون هم Llama 3 70B و هم GPT-4 بدون پرداختن به ریاضیات پاسخ صحیح را دادند. کار خوب متا!
If it takes 1 hour to dry 15 towels under the Sun, how long will it take to dry 20 towels?
برنده: Llama 3 70B و GPT-4 از طریق ChatGPT Plus

مقالات پیشنهادی
من به Gemini 1.5 Pro دسترسی پیدا کردم و از GPT-4 و Gemini 1.0 Ultra بهتر است
آرجون شا
28 فوریه 2024
3. اپل را پیدا کنید
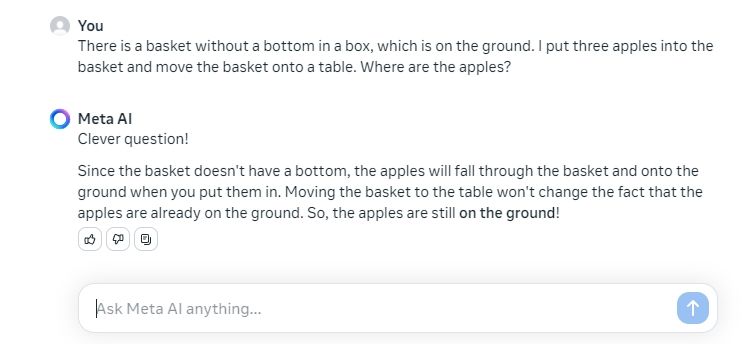
بعدش یه سوال دیگه برای مقایسه قابلیت استدلال Llama 3 و GPT-4 پرسیدم. در این تست، مدل Llama 3 70B به پاسخ درست نزدیک می شود اما از دست می دهد در مورد ذکر جعبه در حالی که مدل GPT-4 به درستی پاسخ می دهد که “سیب ها هنوز روی زمین در داخل جعبه هستند”. من قصد دارم در این دور آن را به GPT-4 بدهم.
There is a basket without a bottom in a box, which is on the ground. I put three apples into the basket and move the basket onto a table. Where are the apples?
برنده: GPT-4 از طریق ChatGPT Plus
4. کدام یک سنگین تر است؟
در حالی که این سوال بسیار ساده به نظر می رسد، بسیاری از مدل های هوش مصنوعی نمی توانند پاسخ درست را دریافت کنند. با این حال، در این آزمایش، هر دو Llama 3 70B و GPT-4 این را دادند پاسخ صحیح. با این حال، Llama 3 گاهی اوقات خروجی اشتباه تولید می کند، بنابراین این را در نظر داشته باشید.
What's heavier, a kilo of feathers or a pound of steel?
برنده: Llama 3 70B و GPT-4 از طریق ChatGPT Plus

5. موقعیت را پیدا کنید
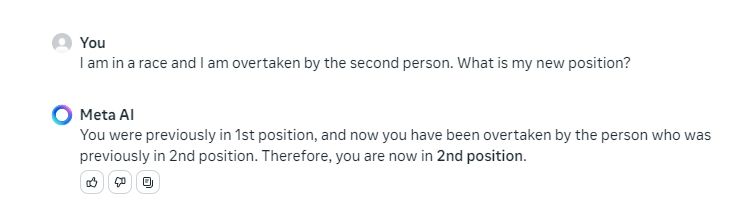
بعد یه سوال منطقی ساده پرسیدم و هر دو مدل پاسخ درستی دادند. جالب است که یک مدل Llama 3 70B بسیار کوچکتر را ببینید که رقیب مدل GPT-4 درجه یک است.
I am in a race and I am overtaken by the second person. What is my new position?
برنده: Llama 3 70B و GPT-4 از طریق ChatGPT Plus
مقالات پیشنهادی
مدلهای هوش مصنوعی Claude 3 Opus در مقابل GPT-4 در مقابل Gemini 1.5 Pro تست شده
آرجون شا
6 مارس 2024
6. حل یک مسئله ریاضی
بعد، یک مجتمع را اداره کردیم مسئله ریاضی در Llama 3 و GPT-4 برای پیدا کردن اینکه کدام مدل برنده این آزمایش است. در اینجا، GPT-4 آزمون را با موفقیت پشت سر می گذارد، اما لاما 3 شکست می خورد برای رسیدن به پاسخ درست هر چند جای تعجب نیست. مدل GPT-4 در معیار ریاضی امتیاز عالی کسب کرده است. به خاطر داشته باشید که من صریحاً از ChatGPT خواستم که از Code Interpreter برای محاسبات ریاضی استفاده نکند.
Determine the sum of the y-coordinates of the four points of intersection of y = x^4 - 5x^2 - x + 4 and y = x^2 - 3x.
برنده: GPT-4 از طریق ChatGPT Plus

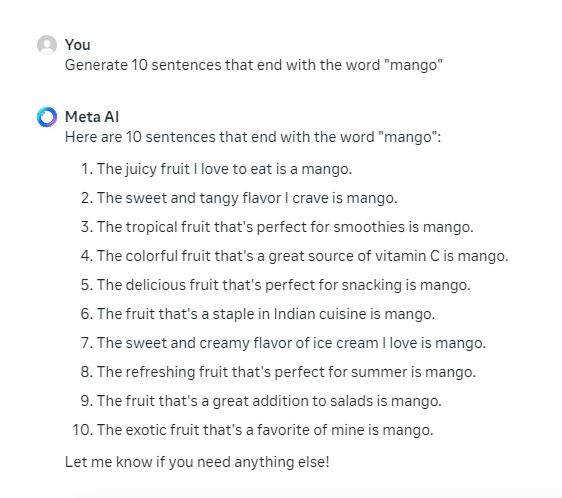
7. دستورالعمل های کاربر را دنبال کنید
پیروی از دستورالعمل های کاربر برای یک مدل هوش مصنوعی و متا بسیار مهم است مدل Llama 3 70B عالی است در آن. تمام 10 جمله ای را که با کلمه “انبه” ختم می شود تولید کرد. GPT-4 فقط میتوانست هشت جمله از این قبیل تولید کند.
Generate 10 sentences that end with the word "mango"
برنده: Llama 3 70B
مقالات پیشنهادی
جمینی اولترا در مقابل GPT-4: گوگل هنوز سس مخفی را ندارد
آرجون شا
12 فوریه 2024
8. تست NIAH
اگرچه Llama 3 در حال حاضر پنجره زمینه طولانی ندارد، ما همچنان تست NIAH را برای بررسی قابلیت بازیابی آن انجام دادیم. مدل Llama 3 70B از a طول زمینه تا 8K توکن. بنابراین من یک سوزن (یک عبارت تصادفی) را در یک متن طولانی 35 هزار کاراکتری (8K نشانه) قرار دادم و از مدل خواستم اطلاعات را پیدا کند. با کمال تعجب، Llama 3 70B متن را در کمترین زمان پیدا کرد. GPT-4 نیز برای یافتن سوزن مشکلی نداشت.
البته این یک است زمینه کوچک، اما زمانی که متا یک مدل Llama 3 را با یک پنجره زمینه بسیار بزرگتر منتشر کرد، دوباره آن را آزمایش خواهم کرد. اما در حال حاضر، Llama 3 قابلیت بازیابی بسیار خوبی را نشان می دهد.
برنده: Llama 3 70B و GPT-4 از طریق ChatGPT Plus
مقالات پیشنهادی
Gemini 1.5 Pro اکنون به صدا گوش می دهد و برای همه در دسترس است
آرجون شا
10 آوریل 2024
من هوش مصنوعی متا را در واتس اپ آزمایش کردم و در اینجا همه چیزهایی که می تواند انجام دهد وجود دارد
آنشومان جین
14 آوریل 2024
Llama 3 vs GPT-4: The Verdict
تقریباً در همه آزمایشها، مدل Llama 3 70B قابلیتهای چشمگیری را نشان داده است، خواه استدلال پیشرفته، پیروی از دستورالعملهای کاربر یا قابلیت بازیابی. فقط در محاسبات ریاضی از مدل GPT-4 عقب است. متا می گوید که Llama 3 بر روی یک مجموعه داده کدگذاری بزرگتر آموزش دیده است عملکرد کدنویسی همچنین باید عالی باشد
به خاطر داشته باشید که ما در حال مقایسه a مدل بسیار کوچکتر با مدل GPT-4 همچنین، Llama 3 یک مدل متراکم است در حالی که GPT-4 بر اساس معماری MoE متشکل از مدلهای 222B 8 ساخته شده است. در ادامه نشان می دهد که متا کار قابل توجهی با خانواده مدل های Llama 3 انجام داده است. زمانی که مدل 500B+ Llama 3 در آینده کاهش یابد، عملکرد بهتری خواهد داشت و ممکن است بهترین مدلهای هوش مصنوعی را شکست دهد.
به جرات می توان گفت که Llama 3 بازی را ارتقا داده است و با منبع باز مدل، متا شکاف را به طور قابل توجهی پر کرد بین مدل های اختصاصی و منبع باز ما تمام این تست ها را روی یک مدل Instruct انجام دادیم. مدلهای تنظیمشده در Llama 3 70B عملکرد استثنایی را ارائه میکنند. جدا از OpenAI، Anthropic و Google، Meta اکنون رسما به مسابقه هوش مصنوعی پیوسته است.
با کُلبه وبسایت و مجله فناوری و ابزارهای هوشمند ،بهترین تکنولوژی، بهترین آینده ، بروز بمانید